OUR RESEARCH
Generative Adversarial Networks for Medical Imaging (MI-GAN)
Medical Image Super-Resolution using GANs
For medical image analysis, there is always an immense need for rich details in an image. In medical imaging, acquiring high-resolution images is challenging and costly as it requires sophisticated and expensive instruments, trained human resources, and often causes operation delays. Deep learning based super resolution techniques can help us to extract rich details from a low-resolution image acquired using the existing devices. We propose a new Generative Adversarial Network (GAN) based architecture for medical images, which maps low-resolution medical images to high-resolution images. The proposed architecture is divided into three steps. In the first step, we use a multi-path architecture to extract shallow features on multiple scales instead of single scale. In the second step, we use a ResNet34 architecture to extract deep features and upscale the features map by a factor of two. In the third step, we extract features of the upscaled version of the image using a residual connection-based mini-CNN and again upscale the feature map by a factor of two. The progressive upscaling overcomes the limitation for previous methods in generating true colors. Finally, we use a reconstruction convolutional layer to map back the upscaled features to a high-resolution image. Our addition of an extra loss term helps in overcoming large errors, thus, generating more realistic and smooth images. We evaluate the proposed architecture on four different medical image modalities: (1) the DRIVE and STARE datasets of retinal fundoscopy images, (2) the BraTS dataset of brain MRI, (3) the ISIC skin cancer dataset of dermoscopy images, and (4) the CAMUS dataset of cardiac ultrasound images. The proposed architecture achieves superior accuracy compared to other state-of-the-art super-resolution architectures.
Read about this work in Nature Scientific Reports
For medical image analysis, there is always an immense need for rich details in an image. In medical imaging, acquiring high-resolution images is challenging and costly as it requires sophisticated and expensive instruments, trained human resources, and often causes operation delays. Deep learning based super resolution techniques can help us to extract rich details from a low-resolution image acquired using the existing devices. We propose a new Generative Adversarial Network (GAN) based architecture for medical images, which maps low-resolution medical images to high-resolution images. The proposed architecture is divided into three steps. In the first step, we use a multi-path architecture to extract shallow features on multiple scales instead of single scale. In the second step, we use a ResNet34 architecture to extract deep features and upscale the features map by a factor of two. In the third step, we extract features of the upscaled version of the image using a residual connection-based mini-CNN and again upscale the feature map by a factor of two. The progressive upscaling overcomes the limitation for previous methods in generating true colors. Finally, we use a reconstruction convolutional layer to map back the upscaled features to a high-resolution image. Our addition of an extra loss term helps in overcoming large errors, thus, generating more realistic and smooth images. We evaluate the proposed architecture on four different medical image modalities: (1) the DRIVE and STARE datasets of retinal fundoscopy images, (2) the BraTS dataset of brain MRI, (3) the ISIC skin cancer dataset of dermoscopy images, and (4) the CAMUS dataset of cardiac ultrasound images. The proposed architecture achieves superior accuracy compared to other state-of-the-art super-resolution architectures.
Read about this work in Nature Scientific Reports
3D CycleGAN model for ultrasound image sequences of intra-muscular skeletal muscle contractions
Advances in sports medicine, rehabilitation applications and diagnostics of neuromuscular disorders are based on the analysis of skeletal muscle contractions. Medical imaging techniques have transformed the study of muscle contractions by allowing to learn the complex patterns of muscle activation. We use deep learning (3D cycleGAN) to model the authentic intra-muscular skeletal muscle contraction pattern using domain-to-domain translation between in silico (simulated) and in vivo (experimental) image sequences of skeletal muscle contraction dynamics. Our results show that there are large differences between the spatial features of in silico and in vivo data, and that a model could be trained to generate authentic spatio-temporal features similar to those obtained from in vivo experimental data.
Read about this work in Biomedical Engineering Online
Advances in sports medicine, rehabilitation applications and diagnostics of neuromuscular disorders are based on the analysis of skeletal muscle contractions. Medical imaging techniques have transformed the study of muscle contractions by allowing to learn the complex patterns of muscle activation. We use deep learning (3D cycleGAN) to model the authentic intra-muscular skeletal muscle contraction pattern using domain-to-domain translation between in silico (simulated) and in vivo (experimental) image sequences of skeletal muscle contraction dynamics. Our results show that there are large differences between the spatial features of in silico and in vivo data, and that a model could be trained to generate authentic spatio-temporal features similar to those obtained from in vivo experimental data.
Read about this work in Biomedical Engineering Online
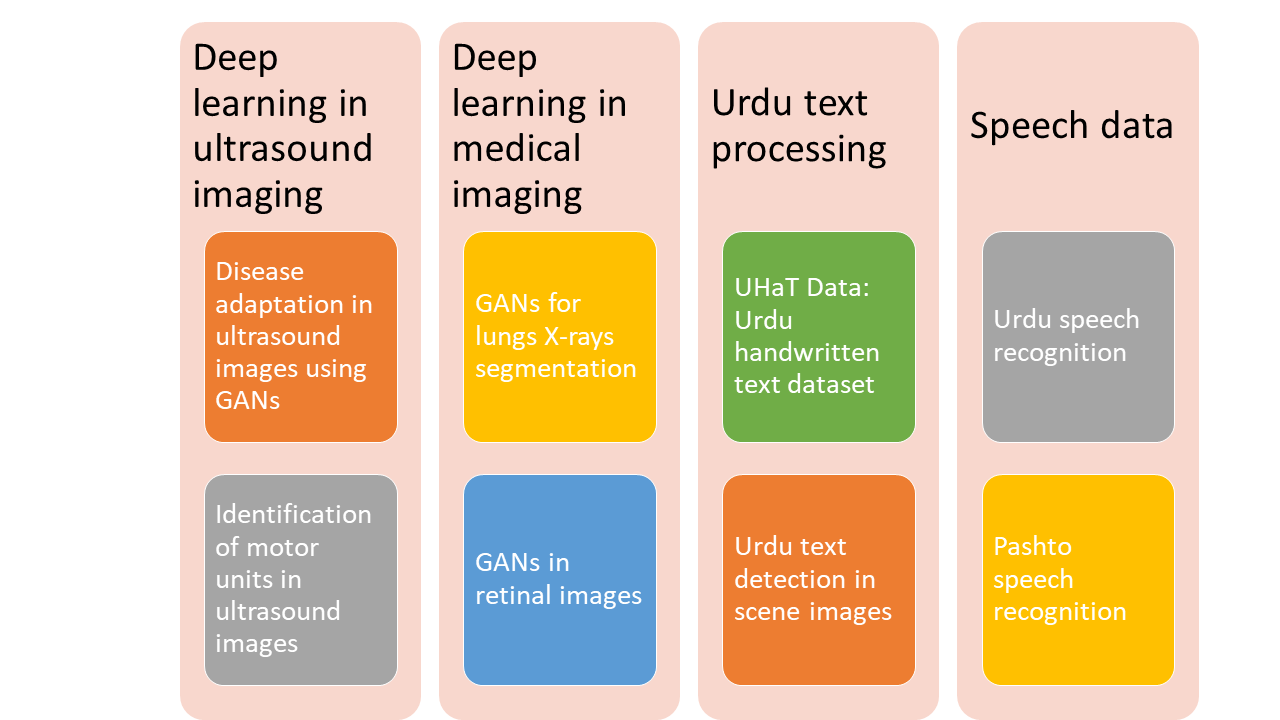
GANs for lungs segmentation in Chest X-rays:
Chest X-ray procedures are considered to be the most popular for diagnosis of chest related diseases. We as a machine learning and medical imaging community, have seen extraordinary interest in the chest x-rays anlaysis and segmentation tasks. For any diagnosis on chest x-rays, accuracte segmentation of the biological object is fundamental. Here, we show how we can use Generative Adversarial Networks (GANs) to perform segmentation of lungs within chest x-rays.
The generator of the GAN generates a segmented mask of a given chest x-ray. Once the generator is trained to generate realistic looking masks, the GAN can now be used to perform segmentation of the lungs on new chest x-ray images.
The full paper is available on IEEE Access ieeexplore.ieee.org/abstract/document/9171249
Chest X-ray procedures are considered to be the most popular for diagnosis of chest related diseases. We as a machine learning and medical imaging community, have seen extraordinary interest in the chest x-rays anlaysis and segmentation tasks. For any diagnosis on chest x-rays, accuracte segmentation of the biological object is fundamental. Here, we show how we can use Generative Adversarial Networks (GANs) to perform segmentation of lungs within chest x-rays.
The generator of the GAN generates a segmented mask of a given chest x-ray. Once the generator is trained to generate realistic looking masks, the GAN can now be used to perform segmentation of the lungs on new chest x-ray images.
The full paper is available on IEEE Access ieeexplore.ieee.org/abstract/document/9171249
Input: Chest X-ray image
Output: Lungs segmentation mask
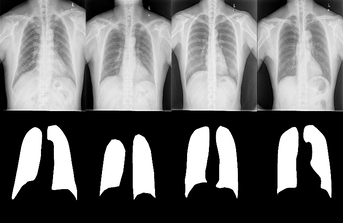
GANs for retinal images:
We propose a new Generative Adversarial Network for Medical Imaging (MI-GAN). The MI-GAN generates synthetic medical images and their segmented masks, which can then be used for the application of supervised analysis of medical images. This work presents MI-GAN for synthesis of retinal images. The MI-GAN method generates precise segmented retinal images better than the existing techniques.
Read the full paper on Springer link.springer.com/article/10.1007/s10916-018-1072-9
Read the book chapter on Springer link.springer.com/chapter/10.1007/978-3-030-40977-7_21
We propose a new Generative Adversarial Network for Medical Imaging (MI-GAN). The MI-GAN generates synthetic medical images and their segmented masks, which can then be used for the application of supervised analysis of medical images. This work presents MI-GAN for synthesis of retinal images. The MI-GAN method generates precise segmented retinal images better than the existing techniques.
Read the full paper on Springer link.springer.com/article/10.1007/s10916-018-1072-9
Read the book chapter on Springer link.springer.com/chapter/10.1007/978-3-030-40977-7_21
Original images (left) and Synthesized images (right)
UHaT Data: Urdu Handwritten Text Dataset
(part of Project UTPro - Urdu Text Processing)
(part of Project UTPro - Urdu Text Processing)
Urdu is the national language of Pakistan and one of the major languages of the world. Research on Urdu hand-written text processing has not been addressed before primarily due to lack of datasets and lack of baseline research. This project is aimed at
The UHaT dataset can be obtained for free from kaggle https://www.kaggle.com/hazrat/uhat-urdu-handwritten-text-dataset
The UHaT dataset is now featured on the IAPR Technical Committee 11 webpage.
- developing a freely available dataset of Urdu handwritten characters. The dataset developed so far comprises of isolated hand-written characters of Urdu, comprising of 1000 images per character.
- Build a deep learning framework for recognition of the isolated words.
The UHaT dataset can be obtained for free from kaggle https://www.kaggle.com/hazrat/uhat-urdu-handwritten-text-dataset
The UHaT dataset is now featured on the IAPR Technical Committee 11 webpage.
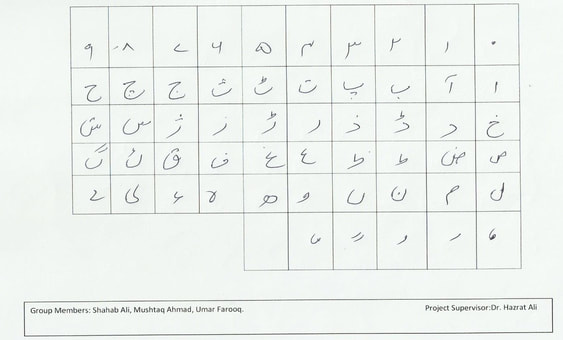
Acknowledgements: This works has been funded by the research grant 21-790/SRGP/R&D/HEC/2016 of Higher Education Commission Islamabad (HEC).
Urdu Speech Recognition
Automatic Speech Recognition (ASR) has been a topic of interest for the last several decades. Today, ASR technology is widely used in our daily life as in Android/iOS devices as robust speech recognition frameworks are available for developed languages. However, for Urdu language, the research work is less developed. This project provides;
- A freely available speech corpus of Urdu isolated words. Currently, the corpus is consists of 250 words. In more refined form, a corpus of 100 words can be obtained for free use (available from download section of this website).
- This work provides a suitable baseline approach based on extraction of Mel-frequency cepstral coefficients and then used for training speech recognition engine such as Hidden Markov Models. The results obtained thus are good baseline for further research work. Particular topic of interest is continuous speech recognition of Urdu.
Machine Learning for Satellite Imagery
----- section to be updated
Text Detection in Scene Images
(joint work with Dr. Khalid Iqbal)
Acknowledgements: This works has been supported by National Natural Science Foundation of China (61105018, 61175020).

Text Extraction. Image Credit: Khalid et al., IJCNN 2014.
Research Collaborations

Dr. Christer Gronlund
|

Prof. Artur S. d'Avila Garcez
|

Dr. Son N. Tran
|

Dr. Emmanouil Benetos
|

Dr. Farhad Bulbul
|
Dr. Christer Gronlund
Biomedical Engineering R & D (MT-FoU)
and
Department of Radiation Science
Umea University, Sweden
www.umu.se/en/staff/christer-gronlund/
Prof. Dr. Artur S. d'Avila Garcez
Center for Machine Learning Research
City University London, UK
http://www.staff.city.ac.uk/~aag/
Dr. Son N. Tran
Lecturer, Information & Communication Technology
University of Tasmania, Australia
https://www.utas.edu.au/profiles/staff/ict/son-tran
Dr. Emmanouil Benetos
Senior Lecturer and Turing Fellow
Queen Mary University London, UK
http://www.eecs.qmul.ac.uk/~emmanouilb/
Dr. Farhad Bulbul
Assistant Professor
Jessore University of Science and Technology, Bangladesh
Biomedical Engineering R & D (MT-FoU)
and
Department of Radiation Science
Umea University, Sweden
www.umu.se/en/staff/christer-gronlund/
Prof. Dr. Artur S. d'Avila Garcez
Center for Machine Learning Research
City University London, UK
http://www.staff.city.ac.uk/~aag/
Dr. Son N. Tran
Lecturer, Information & Communication Technology
University of Tasmania, Australia
https://www.utas.edu.au/profiles/staff/ict/son-tran
Dr. Emmanouil Benetos
Senior Lecturer and Turing Fellow
Queen Mary University London, UK
http://www.eecs.qmul.ac.uk/~emmanouilb/
Dr. Farhad Bulbul
Assistant Professor
Jessore University of Science and Technology, Bangladesh
