|
0 Comments
General Tips for Thesis writing
Version 0.1 How to plan for preparing good thesis. These guidelines are specifically written for my graduate students. I am sharing these here so I may save time otherwise required briefing each student. Please feel free to share with anyone who may benefit. The list is not exhaustive and I may add more points later. The tips are equally useful for planning on writing research papers. Thesis outline Make outline of thesis in advance i.e. make a thesis structure. A typical structure would be:
When writing, always take into consideration comparison of your work with different recent models. Figures Figures such as block diagrams, flow charts should be drawn in MS visio tool, or draw.io tool. Avoid drawing figures in MS office.
For tables insertion: insert tables inside a text box. This will make your life easier otherwise you may struggle a lot with alignment of tables. References:
Acronyms are usually defined on first instance and then used throughout. Abbreviation/Acronyms to be used as given below: Example 1: We use convolutional neural network (CNN) with the …… The reason to use CNN is motivated by ….. Example 2: Generative adversarial networs (GANs) were proposed by Ian Goodfellow. Our work on GANs for medical imaging has appeared in Springer Journal of Medical Systems. Summary Deep learning algorithms produces state-of-the-art results for different machine learning and computer vision tasks. To perform well on a given task, these algorithms require large dataset for training. However, deep learning algorithms lack generalization and suffer from over-fitting whenever trained on small dataset, especially when one is dealing with medical images. For supervised image analysis in medical imaging, having image data along with their corresponding annotated ground-truths is costly as well as time consuming since annotations of the data is done by medical experts manually. In this paper, we propose a new Generative Adversarial Network for Medical Imaging (MI-GAN). The MI-GAN generates synthetic medical images and their segmented masks, which can then be used for the application of supervised analysis of medical images. This work presents MI-GAN for synthesis of retinal images. The MI-GAN method generates precise segmented retinal images better than the existing techniques. The MI-GAN model achieves a dice coefficient of 0.837 on STARE dataset and 0.832 on DRIVE dataset which is state-of-the-art performance on both the datasets. 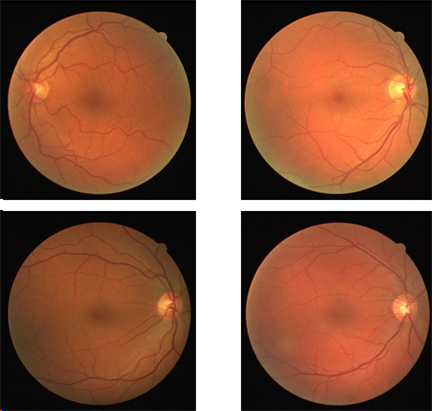 Original images (left) and Synthesized images (right) Motivation Today, majority of the medical professionals use computer-aided medical images for diagnosis purposes. Retinal vessel network analysis gives us information about the status of general system and conditions of the eyes. Ophthalmologists can diagnose early sign of vascular burden due to hypertension and diabetes as well as vision threatening retinal diseases like Retinal Artery Occlusion (RAO) and Retinal Vein Occlusion (RVO) from abnormality in vascular structure. To aid this kind of analysis, automatic vessels segmentation methods have been extensively studied. Recently, deep learning methods have shown potential to produce promising results with higher accuracy, occasionally better than medical specialist in the field of medical imaging. Deep learning also improves efficiency of analyzing data due to its computational and automated nature but most of the medical images are often 3 dimensional (e.g. MRI and CT) and it is difficult as well as inefficient to produce manually annotated images. In general, medical images are inadequate, expensive and offer restricted use due to legal issues (patient privacy). Moreover, the datasets of medical images available publicly often lack consistency in size and annotation. This makes them less useful for training of neural networks, which are data-hungry. This directly limits the development of medical diagnosis systems. So, generation of synthetic images along with their segmented images will help in medical image analysis and provide better diagnosis systems. Remarks
These synthesized images are realistic looking. When used as additional training dataset, the framework helps to enhance the image segmentation performance. The MI-GAN model is capable of learning useful features from a small training set. In our case the training set consisted of only 10 examples from each dataset namely DRIVE and STARE. MI-GAN had less false positive rate at fine vessels and have drawn more clearer lines, as compared to other methods. Human Brain is wonderful and the more we get deeper into the understanding of its functionality, the more exciting and amazing facts we come through. Human brain has perhaps the most remarkable cognitive abilities, and it would take huge processing and computational resources to perform the same recognition tasks by a machine or a robot, which are otherwise done by human brain in a very simple fashion, such as object recognition in images/videos/scenes. For example, the Google Brain project took three days to train itself with 10 million YouTube videos, in order to recognize pictures of cats (using unsupervised features) and came out with a 74.8 percent accuracy of recognizing cats. The experiment involved a usage of 1000 machines with a total 16,000 cores, running over three days, and using parallel mode processing [1]. On the other hand, the human performs similar task without much supervision and an almost perfect accuracy. What is so special about human brain? What gives the cognition abilities to human brain? How many neurons are there in the human brain? Is the human brain larger in size than an Elephant brain? If these and similar questions have ever bothered you, this article is definitely for you. The human beings study animals, rather than animal perform study on human beings. Until recently, scientists believed that all mammals have brains built in the same way, with the number of neurons proportional to the size of the brain. This apparently implies that if two brains are having the same size, it means they have the same number of neurons, and thus the two brains should have same cognitive capabilities, (given the assumption that neuron is the functional processing unit of the brain). Now, the brain of a cow is typically of 400 grams, matching the size of the chimpanzee’s brain, yet, the two species widely differ in terms of complex analytical abilities. Thus, Neuroscientist Suzana Herculano [2] suggests that this hypothesis cannot be true and the size is not the factor which defines the cognition abilities of the brain. For example, if a larger size brain has more cognitive abilities than a smaller because the former has more number of neurons, then, the largest brain on earth must be the one with the highest index of cognition. But, the human brain is just 1.5 kg on average, but an elephant has brain of about 4.5 kg, and the whale has even larger brain with a weight of 9 kg. But still the human brain has more cognition abilities. The size of the brain usually follows the size of the body, but comparing a guerilla brain to human brain does not follow this general notion. A guerilla is almost three times bigger in size than a human body i.e. up to 210 kg of body weight, but its brain is just 0.5 kg, almost one-third of human brain. Energy Facts The human brain is much smaller in comparison to the body mass, contributing to only two percent of the total body mass, yet it consumes 25 percent of the body energy i.e. 500 kilo Calories per day. So, the human brain is larger than it should be and it consumes huge energy, making it more special. The human brain is having larger cerebral cortex than it should be. Then, some of the possible explanations may be; Two different brains of same size may actually have different number of neurons. A larger brain may not necessarily have larger number of neurons. The human brain may have the largest number of neurons, especially in the cerebral cortex. Then, a very important question arises; “What is the total number of neurons in human brain?” Till now, it has been a strong belief that human brain consists of 100 billion (or more) neurons. However, Dr. Suzana Herculano actually proved it wrong. First, where did this belief of 100 billion come from? And no satisfactory answer could be provided for this. Is there any reference in the literature which may prove this number? Again, the answer was NO. So, the neuroscientist came up with her own approach to count the number of neurons in the human brain and this approach is the Brain Soup in which the brain or part of the brain was turned into soup, by dissolving it in a detergent and thus achieving a suspension of free nuclei, just like a soup. The experimentation on various species showed that all brains are not made the same way. It turned out that human brain has 86 billion neurons on average (14 billion less than the previous assumption of 100 billion neurons). Out of the total 86 billion neurons, 16 billion neurons are in the cerebral cortex. If the cerebral cortex is the CPU inside the human CPU, i.e. the functional processing and logical reasoning part of the brain, then, 16 billion is the largest number of neurons that any cortex actually has, which gives a very good explanation of the remarkable cognitive abilities of the human brain. Neurons number vs Brain Size 86 billion neurons in rodents would correspond to a brain size of 36 kg, which is impossible, as 36 kg of brain would roughly require 89 Tons of body, so that the brain may be placed in. Usually, one billion neurons of brain may require 6 kcal energy per day, so the total number of calories required for 86 billion neurons can be calculated by simple mathematics. Energy required by 1 billion neurons (per day) = 6 kcal. Energy required by 86 billion neurons (per day) = 516 kcal. This calculation justifies the size of the human brain vs its daily energy requirements. Science is helping us in understanding human brain and the more we dig deeper into it, the denser the facts are revealed. References [1] http://www.wired.com/wiredscience/2012/06/google-x-neural-network [2] TED Talk by Suzana Herculano http://www.ted.com/speakers/suzana_herculano_houzel.html Credits: The article was origninally published on technologytimes.pk at https://www.technologytimes.pk/mystery-behind-human-brain/
A not so formal discussion with
Prof. S. Semnanian, Director of the Advanced Neuroscience School. (By Hazrat Ali, IBRO – APRC Advanced School Participant) At the Sunday’s dinner hosted by Shahed Beheshti University, Professor Semnanian was kind enough to share table with us. And we wanted to make this session fruitful. Prof. Semnanian was willing and very open in sharing his views and experience. We asked the professor, You have now a massive experience at hand. For us being just at the start of our career, what suggestion would you please share, particularly for the development of a country? The professor took a sigh and then said, Look, there are three types of universities if I put it so. Let us call it type A, B, C. Professors from type A stick to teaching only. They will try to convince you that teaching is the most important and the only important job for you in academia. They are not willing to welcome your research ideas. And as you may see, these are the people who have been in the teaching for the last several decades and it is never easy for them to welcome the transition and change towards a research activity. The type B people have already started doing research, and producing good publications at reputed journals and appreciable impact factor. However, I want to focus on the type C. The type C are the people who are doing research for solving real problems of the society. These problems can be related to indigenous solution to local health problems, energy solutions, traffic management, waste management, or anything you can think about. This is what we have to aim at. And this is what academia should focus on for development of the country. Remember, The transition from type A to type B is difficult but even more challenging is the transition to type C. The change is never going to happen overnight and one should not expect it happen quickly. This will take an entire generation before you fully enter into the new phase. For Master/PhD students:
We are welcoming motivated Master/PhD students for research topics in the area of deep learning, machine learning, image processing, speech processing. If you are a current or potential Master/PhD student and would like to work with us, please feel free to get in touch via email. hazrat DOT ali AT live DOT com Admission Information for Spring 2017 session is available at link below. Last date of submission of forms is 5th January 2017. If you have already missed Spring 2017 session, follow the website for information on Fall 2017 session. http://ciit-atd.edu.pk/Secure/Admissions/CurrentAdmissions.aspx Available Research Topics: 1.Deep Learning for Diabetic eye detection 2.Machine Learning for Seizure classification 3.Emotion Recognition through Facial Expressions 4.Generative Adversarial Networks 5.Applications of Extreme Learning Machines We welcome suggestions on other related topics. Scholarship Resources: If you would like to apply for Master/PhD program at COMSATS Institute of Information Technology Abbottabad and would like to seek financial support for your research studies, explore these scholarships opportunities and get benefit.
Abstract Learning representation from audio data has shown advantages over the hand-crafted features such as Mel Frequency Cepstral Coefficients (MFCC) in many audio applications. In most of the representation learning approaches, the connectionist systems have been used to learn and extract latent features from the fixed length data. In this paper, we propose an approach to combine the learned features and the MFCC features for speaker recognition task, which can be applied to audio scripts of different length. In particular, we study the use of features from different levels of Deep Belief Network for quantizing the audio data into vectors of audio-word counts. These vectors represent the audio scripts of different length that make them easier to train a classifier. We show in the experiment that the audio-word count vectors generated from mixture of DBN features at different layers give better performance than the MFCC features. We also can achieve further improvement by combining the audio-word count vector and the MFCC features. Keywords: Deep Belief Networks, Deep Learning, Mel-Frequency Cepstral Coefficients PDF Online: Final version available at link.springer.com Cite as; Ali, H., Tran, S.N., Benetos, E. et al. Neural Comput & Applic (2016). doi:10.1007/s00521-016-2501-7 Disclaimer: Copyrights with publisher. Use allowed for academic, non-commercial purposes only.  Here is my article on sham publisher. Previously posted on blogger.
See the link below. http://buttertech.blogspot.co.uk/2014/09/what-you-should-know-about-sham.html The cross reference and hyperlink generation in LaTeX is a sensitive feature to the use of underscore. (<_>).
Example 1: \url generates an hyperlink to a webpage and includes the webpage. However, if the url contains an underscore, LaTeX may fail to generate a correct link and may not point to the desired webpage. For example, if the url is www.example.com/page_one. and a user tries to generate the hyperlink by writing the following code; \url{www.example.com/page_one} This may not generate a correct hyperlink. How to solve this problem. The solution is pretty simple. Just type the following instead. \url{www.example.com/page\_one} The only addition is a backslash (\), just before the underscore (_). Example 2: Similarly, if a user refers to a figure/graphics included in a document, and the label contains an underscore, the hyperlink will not be generated and the output PDF document will ??. For example, This has been shown in Figure \ref{example_two} The figure has been included as shown below. \begin{figure} \includegraphics{example.png} \caption{This is an example caption} \label{example_two} \end{figure}. The simple solution to this problem is, remove the underscore (_) from the label name. So, rename the label as \label{exampletwo}. Comments are welcomed. LaTeX Errors displayed in log file:
I found no \bibdata command---while reading file paperbyali.aux I found no \bibstyle command---while reading file paperbyali.aux In a recent submission of my LaTeX source file for a conference, I faced the above errors. This type of error occurs when a user uses BibTex for bibliography. However, I was not using BibTex for bibliography. I put all the references into the main .tex file, and generated the bibliography by using \begin{thebibliography} and \end{thebibliography} which is simply an alternative to .bibTeX for generating bibliography in LaTeX. I compiled my file and generated output successfully. But, as soon as I uploaded it on to the server (easychair.org), Mr. LaTeX would give me the same error. I found no \bibdata command---while reading file paperbyali.aux I found no \bibstyle command---while reading file paperbyali.aux There are two approaches to solve the above problem. First one, I may have gone for generating bibliography using the BibTeX. This would have meant writing up all the references (almost 30 plus in my case) in the BibTeX format, which may be time consuming if you are running short on time. So, I followed the second approach. The server expected the file to contain .bib files, and call to the .bib file. I generated an empty foo.bib file, and made a call to it in the main .tex file, as done in the usual way. However, rather than using \bibliography{foo.bib} for calling the .bib file, I used \nobibliography{foo.bib}. Thus, the bibliography was generated from the references specified in the main .tex file and I got rid of the errors by the server, as now, there was a call to .bib file, which the server was expecting. |
Hazrat Ali
Hazrat Ali is Assistant Professor at Department of Electrical Engineering, COMSATS University Islamabad, Abbottabad Campus, Abbottabad Pakistan. Archives
October 2020
Categories |
 RSS Feed
RSS Feed
